相似度搜索
在许多表示学习应用程序中,搜索最近的向量是核心要素。现代神经网络被训练成将对象转化为向量,使得在向量空间中相近的物体在现实世界中也相近。例如,具有相似含义的文本、视觉上相似的图片,或是属于相同流派的歌曲。
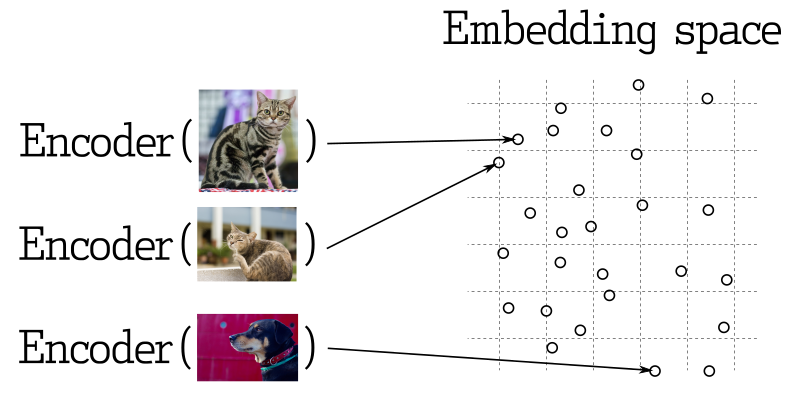
相似度度量
有许多方法来评估向量之间的相似度。在Qdrant中,这些方法被称为相似度度量。选择哪种度量取决于向量的获取方式,尤其是神经网络编码器训练的方法。
Qdrant支持以下最常见的度量类型:
- 点积:
Dot - 余弦相似度:
Cosine - 欧几里得距离:
Euclid
相似度学习模型中最常用的度量是余弦度量。
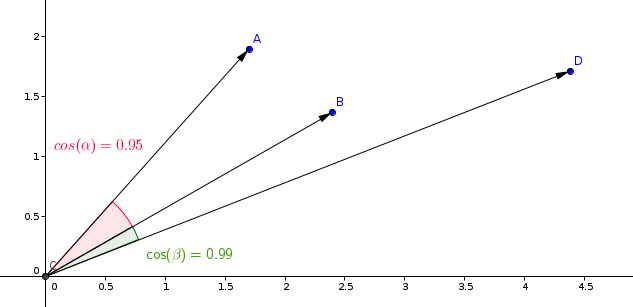
Qdrant通过两个步骤计算该度量,从而实现更高的搜索速度。第一步是在将向量添加到集合时进行向量归一化。这只对每个向量进行一次。
第二步是向量比较。在这种情况下,它等同于点积运算-由于SIMD的快速操作。
查询计划
根据搜索中使用的过滤器,查询执行有几种可能的情况。Qdrant根据可用索引、条件的复杂性和过滤结果的基数选择其中一种查询执行选项。这个过程称为查询计划。
策略选择过程依赖于启发式算法,并且可能因版本而异。然而,一般的原则是:
- 对于每个段独立执行查询计划(有关段的详细信息请参见存储)
- 如果点的数量低于阈值,则优先进行完整扫描
- 在选择策略之前,估计过滤结果的基数
- 如果基数低于阈值,则使用有效载荷索引检索点(请参见索引)
- 如果基数高于阈值,则使用可过滤向量索引
可以通过配置文件以及针对每个集合独立调整阈值。
搜索 API
让我们看一个搜索查询的例子。
REST API - API 模式定义可在此处找到。
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "伦敦"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
在这个例子中,我们要寻找与向量 [0.2, 0.1, 0.9, 0.7] 相似的向量。参数 limit(或其别名 top)指定我们想要检索的最相似结果的数量。
params 键下的值指定搜索的自定义参数。当前可用的参数有:
hnsw_ef- 指定 HNSW 算法的ef参数的值。exact- 是否使用精确搜索(ANN)选项。如果设置为 True,则搜索可能需要很长时间,因为它执行完整扫描以获取精确结果。indexed_only- 使用此选项可以禁用在尚未构建向量索引的段中进行搜索。如果要在更新时尽量减少对搜索性能的影响,这可能很有用。使用此选项可能导致部分结果,如果集合尚未完全索引,请仅在可接受最终一致性的情况下使用它。
由于指定了 filter 参数,搜索仅在满足筛选条件的点之间执行。有关可能的筛选器及其功能的详细信息,请参见筛选器部分。
此 API 的示例结果可能如下所示:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
result 包含按照 score 排序的发现点的列表。
请注意,默认情况下,这些结果中缺少有效负载和向量数据。如何在结果中包含有效负载和向量,请参阅结果中的有效负载和向量部分。
从 v0.10.0 版本开始可用
如果使用了多个向量创建了集合,则应提供要用于搜索的向量的名称:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
搜索仅在具有相同名称的向量之间进行处理。
通过分数过滤结果
除了有效负载过滤外,过滤掉相似度得分低的结果也可能很有用。例如,如果您知道模型的最小接受分数,并且不希望任何低于阈值的相似度结果。在这种情况下,您可以使用搜索查询的 score_threshold 参数。它将排除所有得分低于给定值的结果。
该参数可能会排除较低或较高的分数,具体取决于使用的度量标准。例如,欧几里德度量的较高分数被认为是更远的,因此将被排除。
结果中的有效负载和向量
默认情况下,检索方法不返回任何存储的信息,例如有效负载和向量。附加参数 with_vectors 和 with_payload 可以修改这种行为。
示例:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
参数 with_payload 还可以用于仅包含或排除特定字段:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
批量搜索API
从v0.10.0开始提供
批量搜索API允许通过单个请求执行多个搜索请求。
其语义很简单,n个批量搜索请求等效于n个单独的搜索请求。
这种方法有几个优点。从逻辑上讲,只需要较少的网络连接,这本身就非常有益。
更重要的是,如果批量请求具有相同的filter,则批量请求将通过查询规划器进行高效处理和优化。
这对于非平凡的过滤器来说,对延迟有很大的影响,因为中间结果可以在请求之间共享。
要使用它,只需将您的搜索请求打包在一起。当然,所有常规的搜索请求属性都是可用的。
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "伦敦"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "伦敦"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
此API的结果包含每个搜索请求的数组。
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
推荐API
负向向量是一种实验性功能,并不能保证与所有类型的嵌入一起使用。除了常规搜索外,Qdrant还允许您基于已存储在集合中的多个向量进行搜索。此API在没有涉及神经网络编码器的情况下使用向量搜索已编码的对象。
推荐API允许指定多个正向和负向量ID,服务将将它们合并为一个特定的平均向量。
average_vector = avg(positive_vectors) + ( avg(positive_vectors) - avg(negative_vectors) )
如果只提供一个正向ID,则此请求等效于具有该点的向量的常规搜索。
在负向量中具有较大值的向量分量受到惩罚,而在正向量中具有较大值的向量分量则被放大。将使用此平均向量来查找集合中最相似的向量。
REST API- API模式定义可在此处找到https://qdrant.github.io/qdrant/redoc/index.html#operation/recommend_points
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "伦敦"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
此API的示例结果将如下:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
从v0.10.0开始提供
如果集合是使用多个向量创建的,则推荐请求中应指定向量的名称:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
参数using指定要用于推荐的存储向量。
批量推荐API
可从v0.10.0版本开始使用
与批量搜索API相似,具有相似的用法和优势,它可以批量处理推荐请求。
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "伦敦"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "伦敦"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
该API的结果包含每个推荐请求的数组。
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
分页
可从v0.8.3版本开始使用
搜索和推荐API允许跳过搜索结果的前几个结果,并仅返回从某个特定偏移量开始的结果。
示例:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
相当于检索第11页,每页10条记录。
具有较大偏移值可能会导致性能问题,基于向量的检索方法通常不支持分页。在没有检索到前N个向量的情况下,无法检索到第N个最接近的向量。
然而,使用偏移参数可以通过减少网络流量和存储访问次数来节省资源。
使用offset参数时,需要在内部检索offset + limit个点,但只能从存储中访问那些实际返回的点的载荷和向量。
分组API
从v1.2.0版本开始可用
可以按照某个字段对结果进行分组。当您拥有同一项的多个点,并且希望在结果中避免相同项的冗余时,这将非常有用。
例如,如果您有一个大型文档被分成多个块,并且想要基于每个文档进行搜索或推荐,您可以按文档ID对结果进行分组。
假设有以下载荷的点:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a","b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
通过groups API,您将能够获取每个文档的最佳N个点,假设点的载荷包含文档ID。当然,由于点的数量不足或与查询相对距离较大,可能会有无法满足最佳N点的情况。在每种情况下,group_size是一个尽力而为的参数,类似于limit参数。
搜索分组
REST API (Schema):
POST /collections/{collection_name}/points/search/groups
{
// 与常规搜索API相同
"vector": [1.1],
...,
// 分组参数
"group_by": "document_id", // 要按其分组的字段路径
"limit": 4, // 最大分组数
"group_size": 2, // 每个分组的最大点数
}
推荐分组
REST API(Schema):
POST /collections/{collection_name}/points/recommend/groups
{
// 与常规推荐API相同
"negative": [1],
"positive": [2, 5],
...,
// 分组参数
"group_by": "document_id", // 分组的字段路径
"limit": 4, // 最多分组数
"group_size": 2, // 每个分组的最大点数
}
无论是搜索还是推荐,输出结果如下:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 },
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 },
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
分组按照分组中最高点的得分排序。在每个分组内部,点也会被排序。
如果点的group_by字段是一个数组(例如"document_id": ["a", "b"]),点可以包含在多个分组中(例如"document_id": "a"和document_id: "b")。
该功能严重依赖于提供的group\_by键。为了提高性能,请确保为其创建一个专用索引。限制条件:
group_by参数仅支持关键字和整数有效载荷值。其他类型的有效载荷值将被忽略。- 目前,使用groups时不支持分页,因此不允许使用
offset参数。
在分组中进行查找
从v1.3.0开始可用
对于同一项的不同部分有多个点的情况,往往会在存储的数据中引入冗余。如果点之间共享的信息很少,那么这可能是可以接受的,但如果负载较大,则会成为一个问题,因为它会将存储点所需的存储空间按照分组中的点的数量乘以一个因子进行计算。
使用分组时优化存储的一种方法是,在另一个集合中以同一组id的点为基础将点之间共享的信息存储在单个点中。然后,在使用groups API时,添加with_lookup参数,将这些点的信息添加到每个组中。
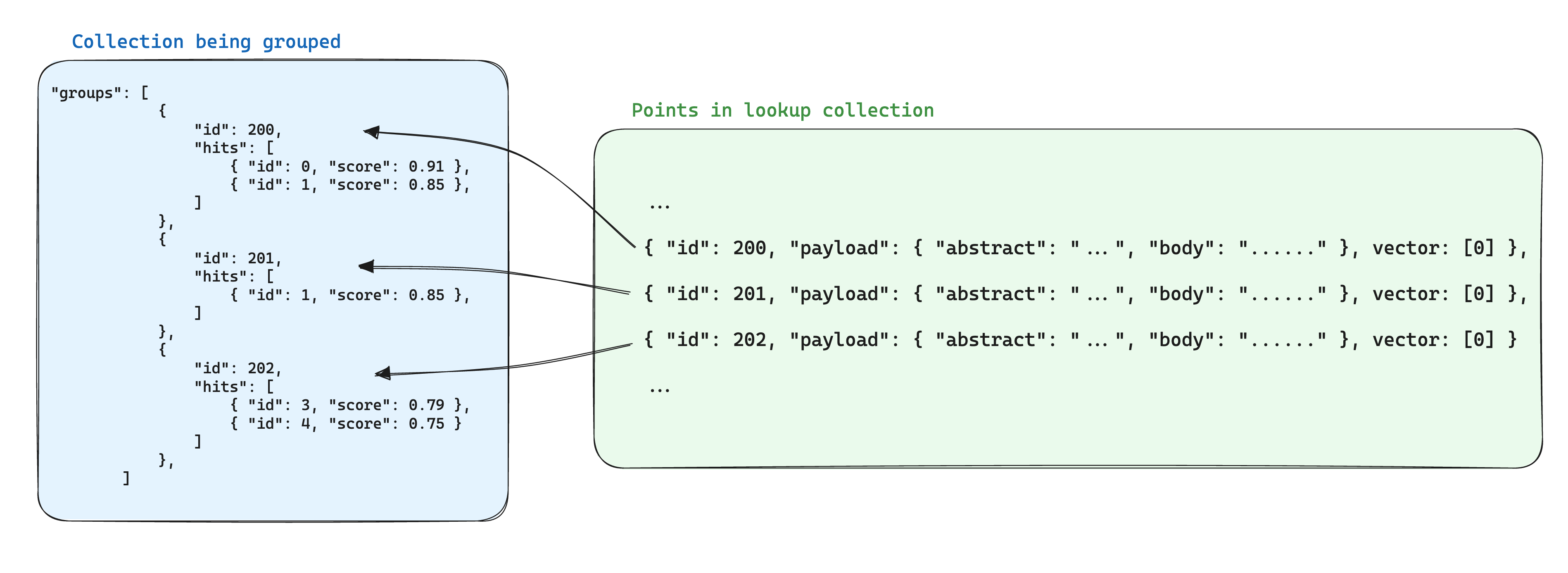
这样做的额外好处是,当组内点共享的信息发生变化时,只需更新单个点即可。
例如,如果你有一个文档集合,你可能希望将它们分块并将这些块所属的点存储在一个单独的集合中,确保将文档所属的点id存储在块点的负载中。
在这种情况下,要将文档中的信息带入按照文档id分组的块中,可以使用with_lookup参数:
POST /collections/chunks/points/search/groups
{
// 与常规搜索API中的参数相同
"vector": [1.1],
...,
// 分组参数
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// 查找参数
"with_lookup": {
// 要查找点的集合名称
"collection": "documents",
// 指定要从查找点的载荷中带入的内容的选项,默认为true
"with_payload": ["title", "text"],
// 指定要从查找点的向量中带入的内容的选项,默认为true
"with_vectors": false
}
}
对于with_lookup参数,还可以使用简写with_lookup="documents",将整个负载和向量均带入,而不需要显式指定。
查找的结果将在每个组下的lookup字段中显示。
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "文档A",
"text": "这是文档A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "文档B",
"text": "这是文档B"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
由于查找是通过与点id直接匹配进行的,任何不是存在(且有效)的点id的组id都将被忽略,并且lookup字段将为空。