LangChain聊天机器人例子
聊天机器人是LLM的核心用例之一。聊天机器人的核心特点是可以进行长时间的对话,并且可以访问用户想要了解的信息。
除了基本的提示和LLMs外,记忆和检索是聊天机器人的核心组成部分。记忆允许聊天机器人记住过去的交互,检索为聊天机器人提供最新的、领域特定的信息。

概述
聊天模型接口是基于消息而不是原始文本的。对于聊天,有几个组件需要考虑:
chat model: 在LangChain中的聊天模型接口的文档和这里的聊天模型集成列表。您也可以将LLMs(详见此处)用于聊天机器人,但聊天模型更具对话的口吻,并原生支持消息接口。prompt template: 提示模板可以方便地组合默认消息、用户输入、聊天历史记录和(可选)其他检索到的上下文。memory: 关于记忆类型的详细文档,请参见此处retriever(可选): 关于检索系统的详细文档,请参见此处。如果您想构建具有领域特定知识的聊天机器人,这些将非常有用。
快速入门
以下是如何创建聊天机器人界面的快速预览。首先安装一些依赖项并设置所需的凭据:
pip install langchain openai
通过简单的聊天模型,我们可以通过向模型传递一个或多个消息来获得聊天完成。
聊天模型将会返回一个消息。
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
chat([HumanMessage(content="将这个英文句子翻译成法文:我喜欢编程。")])
API 参考:
AIMessage(content="J'adore la programmation.", additional_kwargs={}, example=False)
如果我们传递一系列的消息:
messages = [
SystemMessage(content="你是一个翻译英文到法文的有用助手。"),
HumanMessage(content="我喜欢编程。")
]
chat(messages)
AIMessage(content="J'adore la programmation.", additional_kwargs={}, example=False)
然后,我们可以将聊天模型包装在一个ConversationChain中,其中内置了记忆功能,用于记住过去的用户输入和模型输出。
from langchain.chains import ConversationChain
conversation = ConversationChain(llm=chat)
conversation.run("将这个英文句子翻译成法文:我喜欢编程。")
API 参考:
'Je adore la programmation.'
conversation.run("将它翻译成德文。")
'Ich liebe Programmieren.'
记忆
正如我们上面提到的,聊天机器人的核心组件是记忆系统。最简单和最常用的记忆形式之一是ConversationBufferMemory:
- 此记忆允许在
buffer中存储消息 - 当在链中调用时,它返回它存储的所有消息
LangChain 还配备了许多其他类型的记忆。有关记忆类型的详细文档,请参见此处。
现在让我们快速看一下 ConversationBufferMemory。我们可以手动将一些聊天消息添加到记忆中,如下所示:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("嗨!")
memory.chat_memory.add_ai_message("你好吗?")
API参考:
现在,我们可以从我们的记忆中加载。所有Memory类都公开了一个关键方法load_memory_variables,该方法接受任何初始的chain输入,并返回一个添加到chain输入中的记忆变量列表。
由于这种简单的记忆类型在加载记忆时实际上不考虑chain输入,我们现在可以传入一个空输入:
memory.load_memory_variables({})
{'history': '人:你好!\nAI:有什么事?'}
我们还可以使用ConversationBufferWindowMemory保留最近k个交互的滑动窗口。
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "你好"}, {"output": "有什么事"})
memory.save_context({"input": "没什么事"}, {"output": "没什么"})
memory.load_memory_variables({})
{'history': '人:没什么事\nAI:没什么'}
ConversationSummaryMemory是这个主题的扩展。
它会随着时间的推移创建对话的摘要信息。
这种记忆对于较长的对话最为有用,其中完整的消息历史记录会消耗许多token。
from langchain.llms import OpenAI
from langchain.memory import ConversationSummaryMemory
llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context({"input": "你好"}, {"output": "有什么事"})
memory.save_context({"input": "我正在为聊天机器人撰写更好的文档"}, {"output": "噢,听起来很辛苦"})
memory.save_context({"input": "是的,但是这很值得努力"}, {"output": "同意,好的文档很重要!"})
memory.load_memory_variables({})
{'history': '\n人向AI打招呼,AI回应。然后,人提到他们正在为聊天机器人撰写更好的文档,AI回应说听起来很辛苦。人同意值得努力,AI表示同意好的文档很重要。'}
ConversationSummaryBufferMemory进一步扩展了这一点:
它使用token长度而不是交互次数来确定何时刷新交互。
from langchain.memory import ConversationSummaryBufferMemory
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "你好"}, {"output": "有什么事"})
memory.save_context({"input": "没什么事"}, {"output": "没什么"})
API参考:
对话
我们可以深入了解ConversationChain的内部情况。
我们可以指定我们的记忆,ConversationSummaryMemory,并指定prompt。
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"你是一个友善的聊天机器人,正在与人进行对话。"
),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
memory = ConversationBufferMemory(memory_key="chat_history",return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation({"question": "你好"})
API 参考文档:
> 进入新的LLMChain链...
格式化后的提示:
System: 你是一个友好的聊天机器人,正在与人类进行对话。
Human: 你好
> 完成链。
{'question': '你好',
'chat_history': [HumanMessage(content='你好', additional_kwargs={}, example=False),
AIMessage(content='你好!有什么我可以帮助你的吗?', additional_kwargs={}, example=False)],
'text': '你好!有什么我可以帮助你的吗?'}
conversation({"question": "将这个句子从英语翻译成法语:我爱编程。"})
> 进入新的LLMChain链...
格式化后的提示:
System: 你是一个友好的聊天机器人,正在与人类进行对话。
Human: 你好
AI: 你好!有什么我可以帮助你的吗?
Human: 将这个句子从英语翻译成法语:我爱编程。
> 完成链。
{'question': '将这个句子从英语翻译成法语:我爱编程。',
'chat_history': [HumanMessage(content='你好', additional_kwargs={}, example=False),
AIMessage(content='你好!有什么我可以帮助你的吗?', additional_kwargs={}, example=False),
HumanMessage(content='将这个句子从英语翻译成法语:我爱编程。', additional_kwargs={}, example=False),
AIMessage(content='当然!从英语翻译成法语的句子"I love programming"翻译为"J\'adore programmer。"', additional_kwargs={}, example=False)],
'text': '当然!从英语翻译成法语的句子"I love programming"翻译为"J\'adore programmer。"'}
conversation({"question": "现在将句子翻译成德语。"})
> 进入新的LLMChain链...
格式化后的提示:
System: 你是一个友好的聊天机器人,正在与人类进行对话。
Human: 你好
AI: 你好!有什么我可以帮助你的吗?
Human: 将这个句子从英语翻译成法语:我爱编程。
AI: 当然!从英语翻译成法语的句子"I love programming"翻译为"J'adore programmer。"
Human: 现在将句子翻译成德语。
> 完成链。
{'question': '现在将句子翻译成德语。',
'chat_history': [HumanMessage(content='你好', additional_kwargs={}, example=False),
AIMessage(content='你好!有什么我可以帮助你的吗?', additional_kwargs={}, example=False),
HumanMessage(content='将这个句子从英语翻译成法语:我爱编程。', additional_kwargs={}, example=False),
AIMessage(content='当然!从英语翻译成法语的句子"I love programming"翻译为"J\'adore programmer。"', additional_kwargs={}, example=False),
HumanMessage(content='现在将句子翻译成德语。', additional_kwargs={}, example=False),
AIMessage(content='当然!从英语翻译成德语的句子"I love programming"翻译为"Ich liebe das Programmieren。"', additional_kwargs={}, example=False)],
'text': '当然!从英语翻译成德语的句子"I love programming"翻译为"Ich liebe das Programmieren。"'}
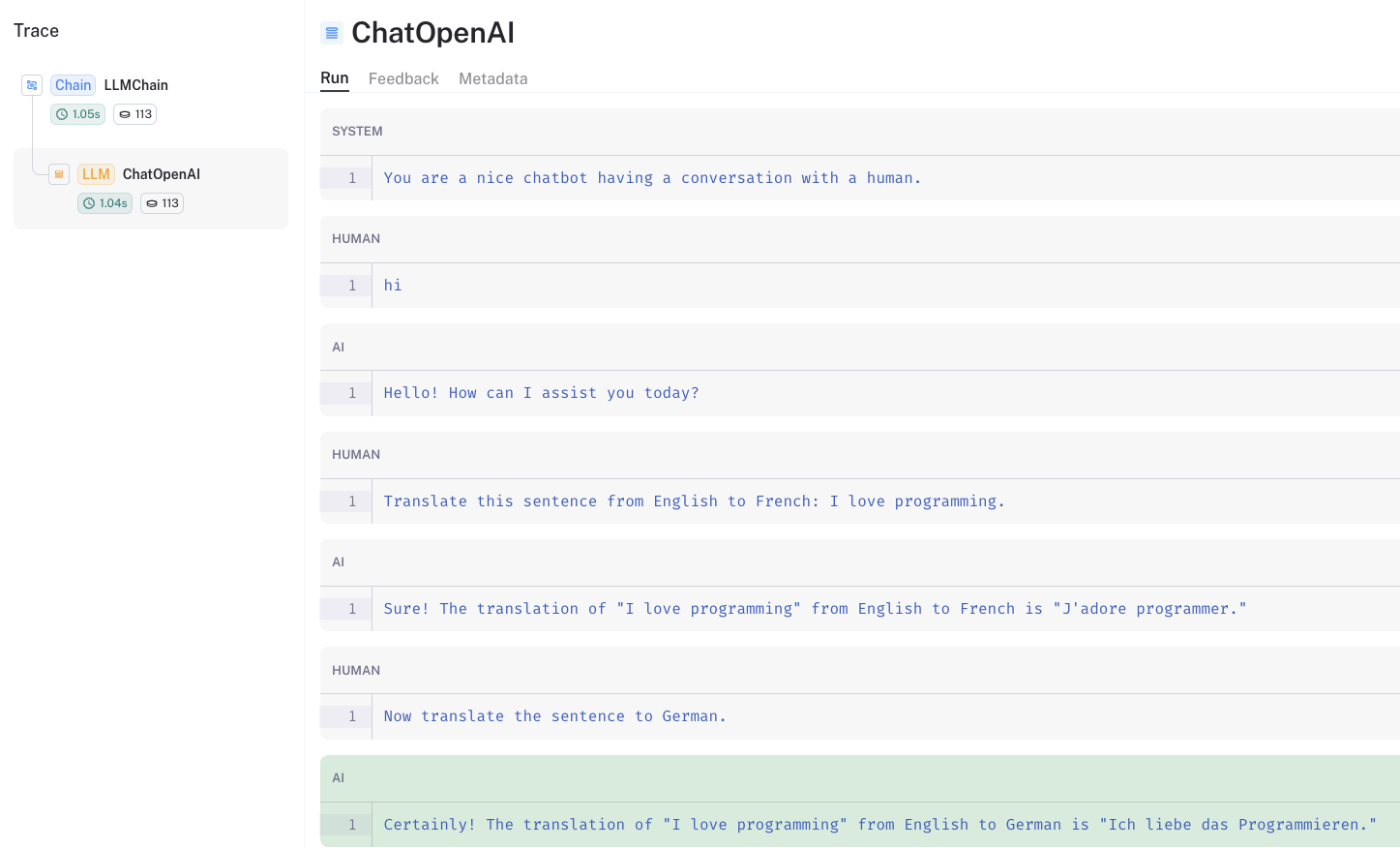
可以通过LangSmith追踪查看保留在提示中的聊天历史。
Chat Retrieval(聊天检索)
现在,假设我们想要通过聊天与文档或其他知识来源进行对话。
这是一个常见的用例,将聊天与文档检索结合在一起。
这使我们能够与模型未经训练的特定信息进行对话。
pip install tiktoken chromadb
加载一个博客文章。
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
API参考:
分割并将其存储为向量。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
API参考:
创建我们的记忆,和之前一样,但是使用ConversationSummaryMemory。
memory = ConversationSummaryMemory(llm=llm, memory_key="chat_history", return_messages=True)
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
llm = ChatOpenAI()
retriever = vectorstore.as_retriever()
qa = ConversationalRetrievalChain.from_llm(llm, retriever=retriever, memory=memory)
API 参考:
qa("Agents 如何使用任务分解?")
{'question': 'Agents 如何使用任务分解?',
'chat_history': [SystemMessage(content='', additional_kwargs={})],
'answer': 'Agents 可以通过以下几种方式使用任务分解:\n\n1.简单引导: Agents 可以使用基于语言模型的引导,将任务分解为子目标。例如,通过提供类似于 “XYZ 的步骤” 或 “为实现 XYZ,需要达成什么子目标?” 的引导,agent 可以生成导致完成整体任务的一系列小步骤。\n\n2.任务特定指令: 可以给 Agents 提供任务特定的指令来指导其规划过程。例如,如果任务是写一本小说,可以指导 agent “写一个故事大纲”。这为任务提供了高层次的结构,并有助于将其分解为较小的组成部分。\n\n3.人类输入: Agents 还可以通过与人类直接交流或利用人类专业知识来获取任务分解的输入。人类可以提供指导和见解,帮助 agent 将复杂任务分解为可管理的子目标。\n\n总的来说,任务分解使 agent 能够将大型任务分解为较小且更易管理的子目标,从而使其能够高效地规划和执行复杂任务。'}
qa("有哪些实现内存支持的各种方式?")
{'question': '有哪些实现内存支持的各种方式?',
'chat_history': [SystemMessage(content='人类问 agent 如何使用任务分解。AI 解释了 agent 可以通过简单引导、任务特定指令和人类输入等多种方式进行任务分解。任务分解使 agent 能够将大型任务分解为较小且更易管理的子目标,从而使其能够高效地规划和执行复杂任务。', additional_kwargs={})],
'answer': '有以下几种实现内存支持的方式:\n\n1.长期内存管理: 这涉及将信息存储和组织在长期内存系统中。 agent 可以检索过去的经验、知识和学到的策略,以指导任务分解过程。\n\n2.互联网访问: agent 可以利用互联网来搜索相关信息并收集资源,以辅助任务分解。这使 agent 能够访问大量信息并在分解过程中利用它。\n\n3.由 GPT-3.5 提供支持的 agent: agent 可以将简单任务委派给由 GPT-3.5 提供支持的 agent。这些 agent 可以执行特定任务或在任务分解方面提供帮助,从而使主要 agent 能够专注于更高层次的规划和决策。\n\n4.文件输出: agent 可以将任务分解的结果存储在文件或文档中。这使得在执行任务过程中能够轻松地检索和参考。\n\n这些内存资源帮助 agent 组织和管理信息,做出明智的决策,并将复杂的任务有效地分解为较小且易于管理的子目标。'}
我们还可以使用 LangSmith 追踪 来探索提示结构。
更深入了解
- 当需要检索时,可以使用对话检索 agent 等 agent 进行检索,同时进行对话。