基于本地知识库的AI问答案例
假设您有一些文本文档(PDF、博客、本地私有数据等),想做一个基于本地知识库的AI问答机器人,基于LangChain很容易就实现这个功能,下面基于LangChain介绍如逐步实现这个问答功能。
- 说明:因为LLM大语言模型训练成本很高,所以大语言模型本身的知识库是不会频繁更新,AI只知道他训练过的内容,对于新的内容或者企业/个人私有数据是不知道的,所以需要把本地的知识库和大语言模型结合起来。
AI问答流程如下
加载(Document loading):首先,我们需要加载我们的本地文本数据,使用LangChain的loader组件可以实现。文档切片(Splitting): 通过LangChain的文本拆分器将Documents切割为指定大小的文本片段(PS:文本切片的目的方便根据问题搜索相关的内容片段,另外一个切片的原因是大语言模型有最大token限制)存储(Storage):将切割好的文档片段,通过嵌入模型计算文档特征向量,然后存储到向量数据库。检索(Retrieval): 根据问题,去向量数据库查询相似的文档片段生成(Generation): 使用LangChain QA链执行问答,将跟问题相关的文档片段和问题一起拼接到自己设计的AI提示词,传给LLM,让AI回答问题。会话(Conversation)(可选): 通过将 Memory 组件添加到的 QA 链中,可以增加AI历史消息记忆功能,方便多乱问答对话。
AI问答流程图如下: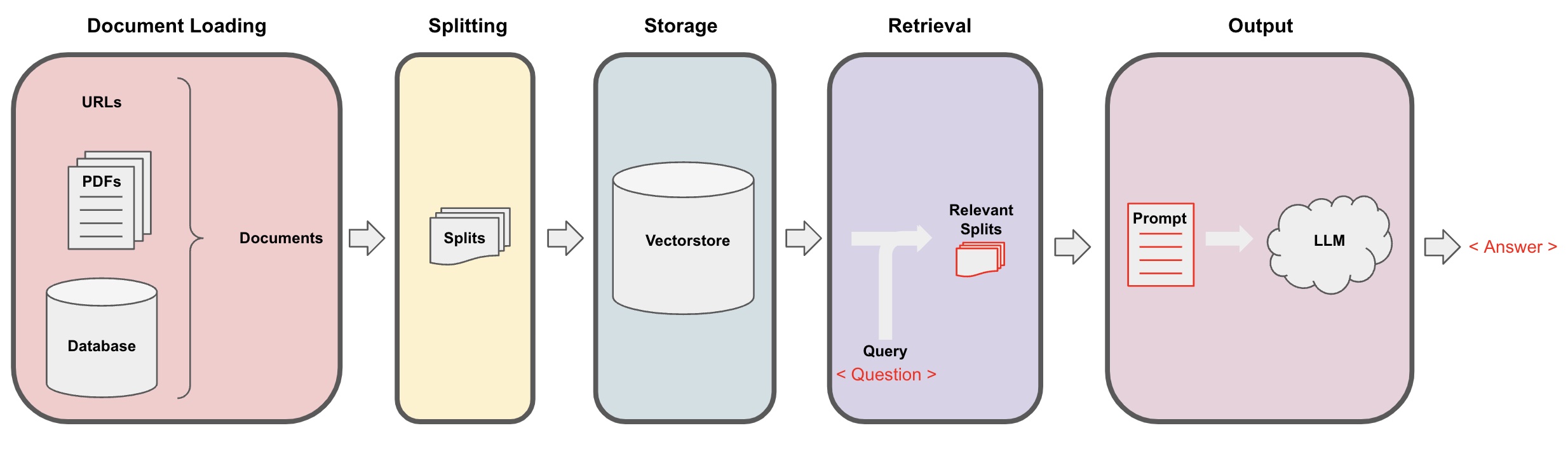
快速开始
为了让你先睹为快,上述流程可以全部包装在一个单一对象VectorstoreIndexCreator中。假设我们基于这篇博客文章创建一个QA问答程序。我们可以用几行代码来实现:
- 提示:本章还是使用openai的大语言模型。
首先设置环境变量并安装软件包:
pip install openai chromadb
export OPENAI_API_KEY="..."
然后运行:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
# 创建loader,通过WebBaseLoader加载url内容
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
现在开始提问:
index.query(“什么是任务分解?”)
任务分解是一种将复杂任务分解为更小、更简单步骤的技术。它可以通过简单提示、任务特定指令或人工输入使用LLM来完成。思维树(Yao et al.2023)是任务分解技术的一个例子,该技术在每一步探索多种推理可能性,并在每一步骤生成多个想法,从而创建树结构
程序跑起来了,但是底层是如何实现的?下面我们一步步分解过程。
Step 1. Load(加载文档数据)
指定一个 DocumentLoader 以将指定的数据加载到 Documents对象。 Document 对象代表一段文本(page_content)和相关元数据。
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- 说明:langchain提供了很多loader加载器,方便加载各类数据,可以参考前面章节。
Step 2. Split(切割文档)
因为大模型提示词有最大token限制,我们不能把太多的文档内容传给AI,通常是把相关的文档片段穿过去就行,所以这里需要对文档切片处理。
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 定义文本分割器,更多的langchain文档分割器,请参考前面章节
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
# 切割文档, 每块文档最大500
all_splits = text_splitter.split_documents(data)
Step 3. Store(向量存储)
为了能够根据问题查询相关的文档片段,我们需要把前面拆分的文档片段,分别使用embedding(嵌入模型)计算文本特征向量,然后存储到向量数据库中。
这里我们使用langchain默认的向量数据库chroma, 然后使用openai的embedding模型。
- 提示: embedding模型也可以选择其他开源的模型替代。
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
# 定义向量数据库,同时设置前面切片的文档数据,然后设置使用openai的嵌入模型,文档片段数据就存储到向量数据库中了
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Step 4. Retrieve(查询相关文档)
根据相似度搜索查询跟问题相关的文档片段
- 提示:这个步骤目的是为了演示向量数据库的相似度搜索功能,第5步langchain封装的问答链自动包含这个步骤的功能。
question = "任务分解的方法是什么?"
# 通过向量数据库查询跟问题相关的文档片段
docs = vectorstore.similarity_search(question)
len(docs)
4
Step 5. Generate(调用AI回答问题)
使用LLM/Chat模型(例如gpt-3.5-turbo)和RetrievalQA链将检索到的文档精简为一个答案。
- 提示:
RetrievalQA是LangChain封装的chain,能够实现基于本地知识库的ai问答。
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
# 定义一个模型,这里使用openai的聊天模型
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# 定义RetrievalQA问答链,设置模型参数,设置前面定义的向量数据库
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectorstore.as_retriever())
# 这里传入你的问题
qa_chain({"query": question})
{
'query': '任务分解的方法有哪些?',
'result': '任务分解的方法包括:\n\n1. 简单提示:这种方法利用简单的提示或问题来引导代理程序将任务分解为更小的子目标。例如,可以提示代理程序“XYZ的步骤”,并要求其列出实现XYZ的子目标。\n\n2. 任务特定指令:在这种方法中,为代理程序提供任务特定指令以指导分解过程。例如,如果任务是写小说,则可以指示代理程序“撰写故事大纲”作为子目标。\n\n3. 人类输入:这种方法涉及将人类输入纳入任务分解过程中。人类可以提供指导、反馈和建议,以帮助代理程序将复杂任务分解为可管理的子目标。\n\n这些方法旨在通过将复杂任务分解为更小、更可管理的部分,实现高效处理复杂任务的目的。'
}
注意,您可以将“LLM”或“ChatModel” 传递到“RetrievalQA”链中。
提示:本教程使用LangChain内置的
RetrievalQAchain实现基于知识库的问答,实际上对于新版的LangChain使用LCEL(LangChain Expression Language)表达式,很容易自定义一个类似的问答链,可以参考LCEL相关章节。
自定义提示词
前面使用RetrievalQA chain的时候没有设置提示词,使用的是langchain内置的提示词模板,下面我们自定义提示词模板。
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
# 提示词模板定义
template ="""根据下面上下文(context)内容回答问题。
如果你不知道答案,就回答不知道,不要试图编造答案。
答案最多3句话,保持答案简洁。
总是在答案结束时说“谢谢你的提问!”
{context}
问题:{question}
答案:"""
# 创建模板
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
#通过chain_type_kwargs参数设置提示词模板
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
AI问答返回参考内容
使用RetrievalQAWithSourcesChain代替RetrievalQA可以返回AI是基于那个文档回答内容。
from langchain.chains import RetrievalQAWithSourcesChain
# 用法跟RetrievalQA一样
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm,retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
接前面基于博客连接回答问题的例子,返回效果如下,可以看到AI是基于那个博客url回答的问题
{
'question':'任务分解的方法是什么?',
'answer':'任务分解的方法包括(1)使用LLM和简单提示,(2)使用特定于任务的说明,以及(3)将人类输入纳入其中。\ n',
'sources':'https://lilianweng.github.io/posts/2023-06-23-agent/'
}