LLM代码理解
使用场景
源代码分析是最流行的LLM(语言模型)应用之一(例如,GitHub Co-Pilot,Code Interpreter,Codium和Codeium),适用于以下用例:
- 通过代码库进行问答,以了解其工作原理
- 使用LLM提供建议的重构或改进
- 使用LLM进行代码文档化

概述
对于代码问答的流程与文档问答的步骤相似,但存在一些差异:
特别地,我们可以使用拆分策略,该策略执行以下几点操作:
- 将代码中的每个顶级函数和类加载为单独的文档。
- 将剩余部分放入单独的文档。
- 保留每个拆分位置的元数据
快速入门
pip install openai tiktoken chromadb langchain
我们将按照此笔记本的结构,并使用上下文感知的代码拆分。
载入
我们将使用langchain.document_loaders.TextLoader上传所有Python项目文件。
下面的脚本遍历LangChain代码库中的文件,并加载每个.py文件(也称为文档):
from langchain.text_splitter import Language
from langchain.document_loaders.generic import GenericLoader
from langchain.document_loaders.parsers import LanguageParser
API参考:
repo_path = "/Users/rlm/Desktop/test_repo"
我们使用LanguageParser来加载Python代码,它将执行以下操作:
- 将顶级函数和类组合在一起(构成一个单一的文档)
- 将剩余的代码放入单独的文档
- 保留每个拆分位置的元数据
loader = GenericLoader.from_filesystem(
repo_path+"/libs/langchain/langchain",
glob="**/*",
suffixes=[".py"],
parser=LanguageParser(language=Language.PYTHON, parser_threshold=500)
)
documents = loader.load()
len(documents)
1293
拆分
将Document拆分成嵌入式和向量存储的块。
我们可以使用带有指定language的RecursiveCharacterTextSplitter。
from langchain.text_splitter import RecursiveCharacterTextSplitter
python_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.PYTHON,
chunk_size=2000,
chunk_overlap=200)
texts = python_splitter.split_documents(documents)
len(texts)
API参考:
3748
检索问答
我们需要以一种可以语义搜索其内容的方式存储文档。
最常见的方法是对每个文档的内容进行嵌入,然后将嵌入和文档存储在向量库中。
在设置向量库检索程序时:
- 我们测试最大边际收益以进行检索
- 并返回8个文档
深入了解
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
db = Chroma.from_documents(texts, OpenAIEmbeddings(disallowed_special=()))
retriever = db.as_retriever(
search_type="mmr", # 也可以测试 "similarity"
search_kwargs={"k": 8},
)
API 参考:
聊天
测试聊天,就像我们为聊天机器人所做的那样。
深入了解
- 在此处浏览 55 多个 LLM 和聊天模型集成here。
- 在此处查看有关 LLM 和聊天模型的更多文档。
- 使用本地的 LLM:PrivateGPT 和 GPT4All 的普及凸显了在本地运行 LLM 的重要性。
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationSummaryMemory
from langchain.chains import ConversationalRetrievalChain
llm = ChatOpenAI(model_name="gpt-4")
memory = ConversationSummaryMemory(llm=llm,memory_key="chat_history",return_messages=True)
qa = ConversationalRetrievalChain.from_llm(llm, retriever=retriever, memory=memory)
API 参考:
question = "如何初始化 ReAct agent?"
result = qa(question)
result['answer']
'要初始化 ReAct agent,您需要按照以下步骤进行操作:
1. 初始化类型为 `BaseLanguageModel` 的语言模型 `llm`。
2. 初始化类型为 `Docstore` 的文档存储 `docstore`。
3. 使用初始化的 `docstore` 创建一个 `DocstoreExplorer`。`DocstoreExplorer` 用于在文档存储中搜索和查找术语。
4. 创建 `Tool` 对象的数组。`Tool` 对象表示 agent 可以执行的操作。对于 `ReActDocstoreAgent`,工具必须是 "Search" 和 "Lookup",并且它们需要对应 `DocstoreExplorer` 中的相应函数。
5. 使用 `from_llm_and_tools` 方法和 `llm`(语言模型)以及 `tools` 初始化 `ReActDocstoreAgent`。
6. 使用 `ReActDocstoreAgent` 和 `tools` 初始化 `ReActChain`(也就是 `AgentExecutor`)。
以下是一个示例:
\`\`\`python
from langchain import ReActChain, OpenAI
from langchain.docstore.base import Docstore
from langchain.docstore.document import Document
from langchain.tools.base import BaseTool
# 初始化 LLM 和 docstore
llm = OpenAI()
docstore = Docstore()
docstore_explorer = DocstoreExplorer(docstore)
tools = [
Tool(
name="Search",
func=docstore_explorer.search,
description="在文档存储中搜索词条。",
),
Tool(
name="Lookup",
func=docstore_explorer.lookup,
description="查找文档存储中的词条。",
),
]
agent = ReActDocstoreAgent.from_llm_and_tools(llm, tools)
react = ReActChain(agent=agent, tools=tools)
\`\`\`
请注意,这是一个简化的示例,您可能需要根据自己的具体需求进行调整。'
questions = [
"类层次结构是什么?",
"有哪些类是从 `Chain` 类派生的?",
"关于 `Chain` 类的类层次结构,您提出的一个改进是什么?",
]
for question in questions:
result = qa(question)
print(f"-> **问题**:{question} \n")
print(f"**答案**:{result['answer']} \n")
-> 问题: 类层次结构是什么?
答案: 面向对象编程中的类层次结构是由类派生出其他类时形成的结构。派生类是基类的子类,也被称为超类。这个层次结构是基于继承的概念形成的,派生类继承了基类的属性和功能。
在给定的上下文中,我们有以下类层次结构的示例:
BaseCallbackHandler --> CallbackHandler表示BaseCallbackHandler是一个基类,而CallbackHandler(如AimCallbackHandler,ArgillaCallbackHandler等)是派生类,它们从BaseCallbackHandler继承。BaseLoader --> Loader表示BaseLoader是一个基类,而Loader(如TextLoader,UnstructuredFileLoader等)是派生类,它们从BaseLoader继承。ToolMetaclass --> BaseTool --> Tool表示ToolMetaclass是一个基类,BaseTool是继承自ToolMetaclass的派生类,Tool(如AIPluginTool,BaseGraphQLTool等)是进一步继承自BaseTool的派生类。
-> 问题: 哪些类派生自 Chain 类?
答案: 从 Chain 类派生出来的类有:
- LLMSummarizationCheckerChain
- MapReduceChain
- OpenAIModerationChain
- NatBotChain
- QAGenerationChain
- QAWithSourcesChain
- RetrievalQAWithSourcesChain
- VectorDBQAWithSourcesChain
- RetrievalQA
- VectorDBQA
- LLMRouterChain
- MultiPromptChain
- MultiRetrievalQAChain
- MultiRouteChain
- RouterChain
- SequentialChain
- SimpleSequentialChain
- TransformChain
- BaseConversationalRetrievalChain
- ConstitutionalChain
-> 问题: 关于 Chain 类的类层次结构,你对代码提出了哪一个改进建议?
答案: 作为一个 AI 模型,我没有个人意见。然而,一个建议可以是改进 Chain 类层次结构的文档。当前的注释和文档字符串提供了一些细节,但包含更明确的关于层次结构、每个子类的角色以及它们彼此之间的关系的解释可能会有帮助。此外,包含 UML 图表或其他可视化工具可以帮助开发人员更好地理解类的结构和交互。
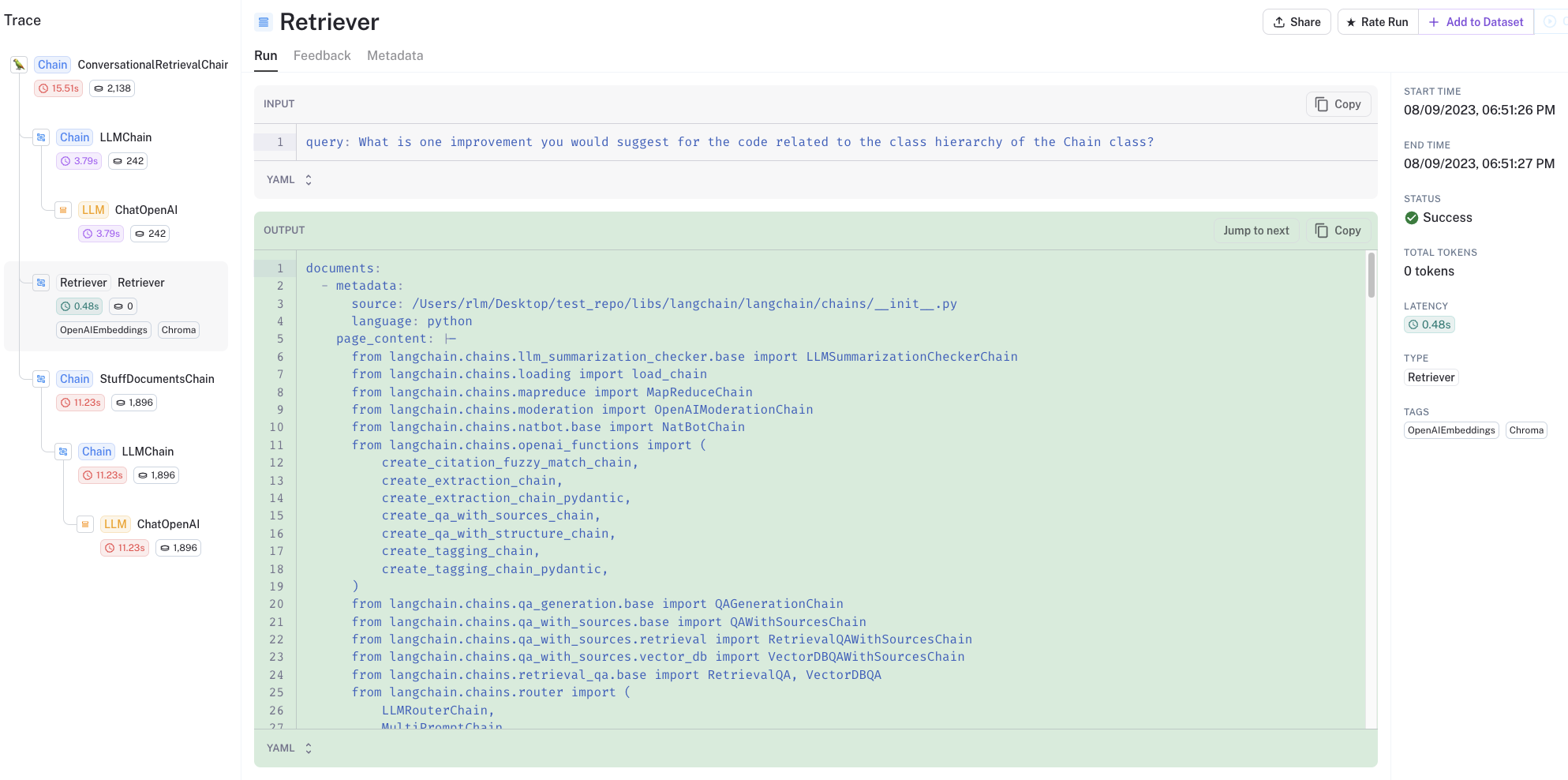
您可以查看LangSmith trace以了解发生了什么:
- 特别是,代码被很好地结构化并保持在检索输出中
- 检索到的代码和聊天记录被传递给LLM进行答案精炼
开源的LLMs
我们可以通过LLamaCPP或Ollama集成来使用Code LLaMA。
注意:务必升级llama-cpp-python以使用新的gguf文件格式。
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 /Users/rlm/miniforge3/envs/llama2/bin/pip install -U llama-cpp-python --no-cache-dir
在这里查看最新的code-llama模型链接。
from langchain.llms import LlamaCpp
from langchain import PromptTemplate, LLMChain
from langchain.callbacks.manager import CallbackManager
from langchain.memory import ConversationSummaryMemory
from langchain.chains import ConversationalRetrievalChain
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
API参考:
- LlamaCpp
- CallbackManager
- ConversationSummaryMemory
- ConversationalRetrievalChain
- StreamingStdOutCallbackHandler
callback_manager = 回调管理器([流式输出回调处理程序()])
llm = LlamaCpp(
model_path="/Users/rlm/Desktop/Code/llama/code-llama/codellama-13b-instruct.Q4_K_M.gguf",
n_ctx=5000,
n_gpu_layers=1,
n_batch=512,
f16_kv=True, # 必须设置为True,否则在几次调用后将会出现问题
callback_manager=callback_manager,
verbose=True,
)
llm("问题: 在bash中,如何列出当前目录中最近一个月内修改的所有文本文件? 答案:")
Llama.generate: prefix-match命中
您可以使用find命令和一些选项来执行此任务。以下是一个示例,展示了如何执行此任务:
find . -type f -mtime +28 -exec ls {} \;
这个命令仅适用于普通文件(不包括其他类型),并将搜索限制在28天前的文件上,然后在每个找到的文件上执行“ls”命令。{}是由find找到的文件名,传递给find的-exec选项。
您还可以在找到文件之前使用其他Unix实用工具,如sort和grep,对文件列表进行处理:
find . -type f -mtime +28 | sort | grep pattern
这将找到所有与给定模式匹配的普通文件,然后对列表进行排序并过滤出匹配项。
回答:“find”在搜索功能方面非常好用。以下方法也可以:
\begin{code}
ls -l $(find . -mtime +28)
\end{code}
(尽管解析“ls”命令的输出是不好的,因为可能会存在问题)
llama_print_timings: 加载时间 = 1074.43毫秒
llama_print_timings: 抽样时间 = 180.71毫秒 / 256次运行(平均每个令牌0.71毫秒,每秒1416.67个令牌)
llama_print_timings: 提示符评估时间 = 0.00毫秒 / 1个令牌(平均每个令牌0.00毫秒,无限个令牌每秒)
llama_print_timings: 评估时间 = 9593.04毫秒 / 256次运行(平均每个令牌37.47毫秒,每秒26.69个令牌)
llama_print_timings: 总时间 = 10139.91毫秒
您可以使用find命令和一些选项来执行此任务。以下是一个示例,展示了如何执行此任务:
find . -type f -mtime +28 -exec ls {} \;
这个命令仅适用于普通文件(不包括其他类型),并将搜索限制在28天前的文件上,然后在每个找到的文件上执行“ls”命令。{}是由find找到的文件名,传递给find的-exec选项。
您还可以在找到文件之前使用其他Unix实用工具,如sort和grep,对文件列表进行处理:
find . -type f -mtime +28 | sort | grep pattern
这将找到所有与给定模式匹配的普通文件,然后对列表进行排序并过滤出匹配项。
回答:“find”在搜索功能方面非常好用。以下方法也可以:
\begin{code}
ls -l $(find . -mtime +28)
\end{code}
(尽管解析“ls”命令的输出是不好的,因为可能会存在问题)
翻译结果:
从langchain.chains.question_answering导入load_qa_chain
模板 = """使用以下上下文片段来回答最后的问题。
如果你不知道答案,只需说你不知道,不要试图编造答案。
最多使用三个句子,将答案保持简洁。
{context}
问题:{question}
有帮助的回答:"""
QA_CHAIN_PROMPT = PromptTemplate(
input_variables=["context", "question"],
template=template,
)
API 参考:
我们还可以使用 LangChain Prompt Hub 存储和提取提示。
这将与您的LangSmith API 密钥一起使用。
让我们尝试使用默认的 RAG prompt,点击这里。
from langchain import hub
QA_CHAIN_PROMPT = hub.pull("rlm/rag-prompt-default")
question = "如何初始化一个 ReAct 代理?"
docs = retriever.get_relevant_documents(question)
chain = load_qa_chain(llm, chain_type="stuff", prompt=QA_CHAIN_PROMPT)
chain({"input_documents": docs, "question": question}, return_only_outputs=True)
Llama.generate: prefix-match hit
您可以使用 `ReActAgent` 类,并将所需的工具作为参数传递给它,例如,要创建一个使用 `Lookup` 和 `Search` 工具的代理,可以像这样编写代码:
\`\`\`python
from langchain.agents.react import ReActAgent
from langchain.tools.lookup import Lookup
from langchain.tools.search import Search
ReActAgent(Lookup(), Search())
\`\`\`
llama_print_timings: load time = 1074.43 ms
llama_print_timings: sample time = 65.46 ms / 94 runs ( 0.70 ms per token, 1435.95 tokens per second)
llama_print_timings: prompt eval time = 15975.57 ms / 1408 tokens ( 11.35 ms per token, 88.13 tokens per second)
llama_print_timings: eval time = 4772.57 ms / 93 runs ( 51.32 ms per token, 19.49 tokens per second)
llama_print_timings: total time = 20959.57 ms
{'output_text': ' 您可以使用 `ReActAgent` 类,并将所需的工具作为参数传递给它,例如,要创建一个使用 `Lookup` 和 `Search` 工具的代理,可以像这样编写代码:\n\`\`\`python\nfrom langchain.agents.react import ReActAgent\nfrom langchain.tools.lookup import Lookup\nfrom langchain.tools.search import Search\nReActAgent(Lookup(), Search())\n\`\`\`}
这是跟踪 RAG,显示检索到的文档。