ChatGLM.cpp
github地址: https://github.com/li-plus/chatglm.cpp
这是 ChatGLM-6B 和 ChatGLM2-6B 的C++实现,以及更多适用于MacBook实时聊天的LLM。

功能
亮点:
- 基于 ggml 的纯C++实现,与 llama.cpp 的工作方式相同。
- 采用int4/int8量化的内存高效CPU推理加速,并优化了KV缓存和并行计算。
- 带打字机效果的流生成。
- 提供Python绑定、Web演示、API服务器等更多可能性。
支持矩阵:
- 硬件:x86/ARM CPU、NVIDIA GPU、Apple Silicon GPU
- 平台:Linux、MacOS、Windows
- 模型:ChatGLM-6B、ChatGLM2-6B、CodeGeeX2、Baichuan-13B、Baichuan-7B、Baichuan-13B、Baichuan2
开始使用
准备工作
将ChatGLM.cpp仓库克隆到本地机器上:
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp
如果在克隆仓库时忘记使用--recursive标志,可以在chatglm.cpp文件夹中运行以下命令:
git submodule update --init --recursive
量化模型
安装加载和量化Hugging Face模型所需的包:
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers sentencepiece
使用convert.py将ChatGLM-6B或ChatGLM2-6B转换为量化的GGML格式。例如,要将fp16原始模型转换为q4_0(量化int4)GGML模型,运行以下命令:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o chatglm-ggml.bin
原始模型(-i)可以是一个HuggingFace模型名称,也可以是您预先下载的模型的本地路径。目前支持的模型有:
- ChatGLM-6B:
THUDM/chatglm-6b,THUDM/chatglm-6b-int8,THUDM/chatglm-6b-int4 - ChatGLM2-6B:
THUDM/chatglm2-6b,THUDM/chatglm2-6b-int4 - CodeGeeX2:
THUDM/codegeex2-6b,THUDM/codegeex2-6b-int4 - Baichuan & Baichuan2:
baichuan-inc/Baichuan-13B-Chat,baichuan-inc/Baichuan2-7B-Chat,baichuan-inc/Baichuan2-13B-Chat
您可以自由选择以下量化类型之一,通过指定-t来指定:
q4_0:使用fp16尺度的4位整数量化。q4_1:使用fp16尺度和最小值的4位整数量化。q5_0:使用fp16尺度的5位整数量化。q5_1:使用fp16尺度和最小值的5位整数量化。q8_0:使用fp16尺度的8位整数量化。f16:半精度浮点权重,无量化。f32:单精度浮点权重,无量化。
对于LoRA模型,请添加-l标志将您的LoRA权重合并到基础模型中。
构建和运行
使用CMake编译项目:
cmake -B build
cmake --build build -j --config Release
现在,您可以通过运行以下命令与量化的ChatGLM-6B模型进行交互:
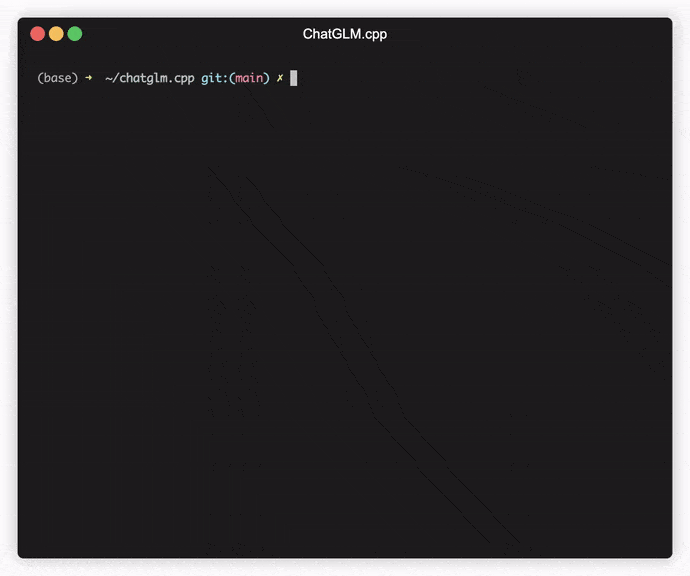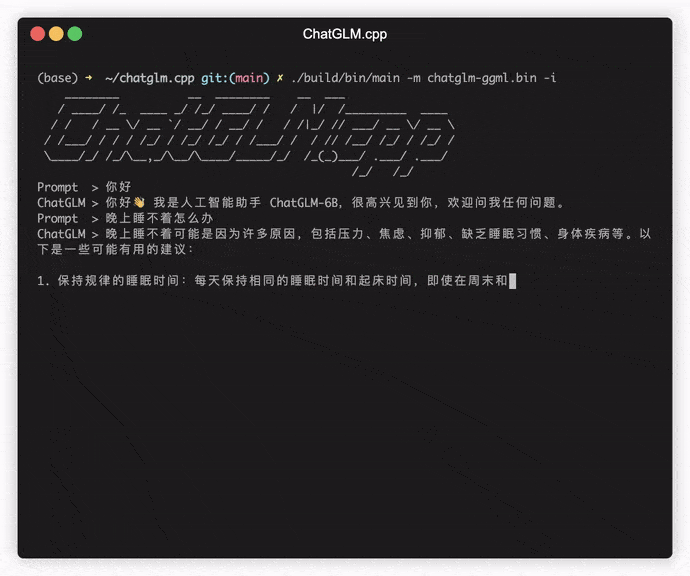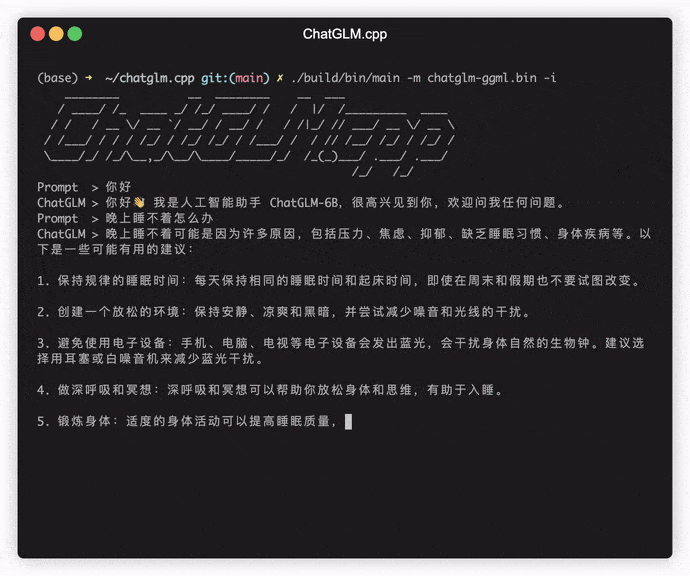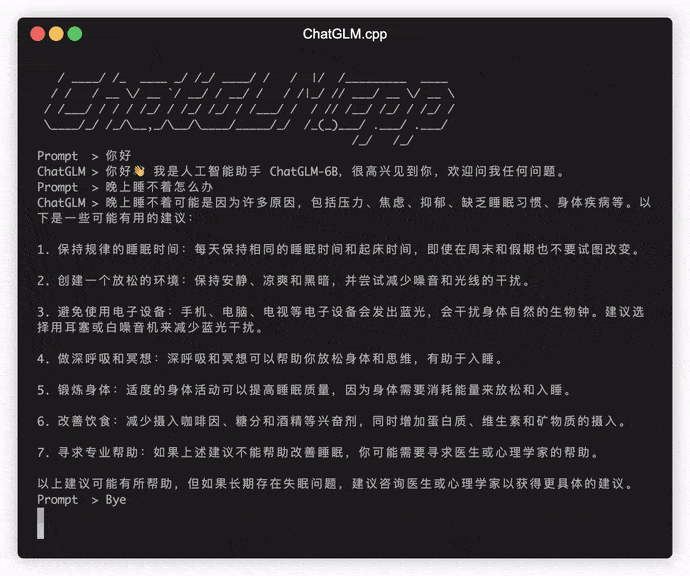
./build/bin/main -m chatglm-ggml.bin -p 你好
要在交互模式下运行模型,请添加-i标志。例如:
./build/bin/main -m chatglm-ggml.bin -i
在交互模式下,您的聊天历史将作为下一轮对话的上下文。
运行./build/bin/main -h来探索更多选项!
尝试其他模型
ChatGLM2-6B模型
python3 chatglm_cpp/convert.py -i THUDM/chatglm2-6b -t q4_0 -o chatglm2-ggml.bin
./build/bin/main -m chatglm2-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
CodeGeeX2模型
$ python3 chatglm_cpp/convert.py -i THUDM/codegeex2-6b -t q4_0 -o codegeex2-ggml.bin
$ ./build/bin/main -m codegeex2-ggml.bin --temp 0 --mode generate -p "\"
"
def bubble_sort(list):
for i in range(len(list) - 1):
for j in range(len(list) - 1):
if list[j] > list[j + 1]:
list[j], list[j + 1] = list[j + 1], list[j]
return list
print(bubble_sort([5, 4, 3, 2, 1]))
Baichuan-13B-Chat
python3 chatglm_cpp/convert.py -i baichuan-inc/Baichuan-13B-Chat -t q4_0 -o baichuan-13b-chat-ggml.bin
./build/bin/main -m baichuan-13b-chat-ggml.bin -p 你好 --top_k 5 --top_p 0.85 --temp 0.3 --repeat_penalty 1.1
Baichuan2-7B-Chat
python3 chatglm_cpp/convert.py -i baichuan-inc/Baichuan2-7B-Chat -t q4_0 -o baichuan2-7b-chat-ggml.bin
./build/bin/main -m baichuan2-7b-chat-ggml.bin -p 你好 --top_k 5 --top_p 0.85 --temp 0.3 --repeat_penalty 1.05
Baichuan2-13B-Chat
python3 chatglm_cpp/convert.py -i baichuan-inc/Baichuan2-13B-Chat -t q4_0 -o baichuan2-13b-chat-ggml.bin
./build/bin/main -m baichuan2-13b-chat-ggml.bin -p 你好 --top_k 5 --top_p 0.85 --temp 0.3 --repeat_penalty 1.05
使用BLAS
BLAS库可以集成以进一步加速矩阵乘法。然而,在某些情况下,使用BLAS可能会导致性能下降。是否启用BLAS应取决于基准测试的结果。
Accelerate Framework
Accelerate Framework在macOS上会自动启用。要禁用它,添加CMake标志-DGGML_NO_ACCELERATE=ON。
OpenBLAS
OpenBLAS提供了CPU加速。添加CMake标志-DGGML_OPENBLAS=ON以启用它。
cmake -B build -DGGML_OPENBLAS=ON && cmake --build build -j
cuBLAS
cuBLAS使用NVIDIA GPU加速BLAS。添加CMake标志-DGGML_CUBLAS=ON以启用它。
cmake -B build -DGGML_CUBLAS=ON && cmake --build build -j
请注意,当前的GGML CUDA实现非常缓慢。社区正在努力优化它。
Metal
MPS(Metal Performance Shaders)允许在强大的Apple Silicon GPU上运行计算。添加CMake标志-DGGML_METAL=ON以启用它。
cmake -B build -DGGML_METAL=ON && cmake --build build -j
Python绑定
Python绑定提供了类似于原始的Hugging Face ChatGLM(2)-6B的高级chat和stream_chat接口。
安装
从PyPI安装(推荐):将在您的平台上触发编译。
pip install -U chatglm-cpp
要在NVIDIA GPU上启用cuBLAS加速:
CMAKE_ARGS="-DGGML_CUBLAS=ON" pip install -U chatglm-cpp
要在Apple M1芯片设备上启用Metal:
CMAKE_ARGS="-DGGML_METAL=ON" pip install -U chatglm-cpp
您也可以从源代码安装。添加相应的加速器CMAKE_ARGS。
pip install git+https://github.com/li-plus/chatglm.cpp.git@main
pip install .
使用预转换的ggml模型
以下是使用chatglm_cpp.Pipeline加载GGML模型并与其聊天的简单演示。首先进入示例文件夹(cd examples),然后启动Python交互式 shell:
>>> import chatglm_cpp
>>>
>>> pipeline = chatglm_cpp.Pipeline("../chatglm-ggml.bin")
>>> pipeline.chat(["你好"])
'你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。'
要在流式聊天中使用,请运行以下Python示例:
python3 cli_chat.py -m ../chatglm-ggml.bin -i
启动网页演示以在浏览器中聊天:
python3 web_demo.py -m ../chatglm-ggml.bin

对于其他模型:
ChatGLM2-6B
python3 cli_chat.py -m ../chatglm2-ggml.bin -p 你好 --temp 0.8 --top_p 0.8 # CLI演示
python3 web_demo.py -m ../chatglm2-ggml.bin --temp 0.8 --top_p 0.8 # 网页演示
CodeGeeX2
python3 cli_chat.py -m ../codegeex2-ggml.bin --temp 0 --mode generate -p "\
"
python3 web_demo.py -m ../codegeex2-ggml.bin --temp 0 --max_length 512 --mode generate --plain
Baichuan-13B-Chat
python3 cli_chat.py -m ../baichuan-13b-chat-ggml.bin -p 你好 --top_k 5 --top_p 0.85 --temp 0.3 --repeat_penalty 1.1 # CLI演示
python3 web_demo.py -m ../baichuan-13b-chat-ggml.bin --top_k 5 --top_p 0.85 --temp 0.3 --repeat_penalty 1.1 # 网页演示
Baichuan2-7B-Chat
python3 cli_chat.py -m ../baichuan2-7b-chat-ggml.bin -p 你好 --top_k 5 --top_p 0.85 --temp 0.3 --repeat_penalty 1.05 # CLI演示
python3 web_demo.py -m ../baichuan2-7b-chat-ggml.bin --top_k 5 --top_p 0.85 --temp 0.3 --repeat_penalty 1.05 # 网页演示
Baichuan2-13B-Chat
python3 cli_chat.py -m ../baichuan2-13b-chat-ggml.bin -p 你好 --top_k 5 --top_p 0.85 --temp 0.3 --repeat_penalty 1.05 # CLI演示
python3 web_demo.py -m ../baichuan2-13b-chat-ggml.bin --top_k 5 --top_p 0.85 --temp 0.3 --repeat_penalty 1.05 # 网页演示
一行代码加载和优化Hugging Face LLMs
有时候,在事先将中间的GGML模型转换并保存下来可能会不太方便。这里提供了一种直接从原始的Hugging Face模型加载的选项,可以在一分钟内将其量化为GGML模型,并开始服务。您只需要用Hugging Face模型的名称或路径替换GGML模型路径就可以了。
>>> import chatglm_cpp
>>>
>>> pipeline = chatglm_cpp.Pipeline("THUDM/chatglm-6b", dtype="q4_0")
Loading checkpoint shards: 100%|██████████████████████████████████| 8/8 [00:10> pipeline.chat(["你好"])
'你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。'
同样地,在任何示例脚本中,将GGML模型路径替换为Hugging Face模型,就可以正常工作。例如:
python3 cli_chat.py -m THUDM/chatglm-6b -p 你好 -i
API 服务器
我们支持各种类型的 API 服务器,用于与流行的前端集成。可以通过以下方式安装额外的依赖:
pip install 'chatglm-cpp[api]'
请记得添加相应的 CMAKE_ARGS 来启用加速。
LangChain API
启动 LangChain 的 API 服务器:
MODEL=./chatglm2-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000
使用 curl 测试 API 端点:
curl http://127.0.0.1:8000 -H 'Content-Type: application/json' -d '{"prompt": "你好"}'
使用 LangChain 运行:
>>> from langchain.llms import ChatGLM
>>>
>>> llm = ChatGLM(endpoint_url="http://127.0.0.1:8000")
>>> llm.predict("你好")
'你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'
有关更多选项,请参考 examples/langchain_client.py 和 LangChain ChatGLM 集成。
OpenAI API
启动兼容 OpenAI chat completions protocol 的 API 服务器:
MODEL=./chatglm2-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000
使用 curl 测试端点:
curl http://127.0.0.1:8000/v1/chat/completions -H 'Content-Type: application/json' \
-d '{"messages": [{"role": "user", "content": "你好"}]}'
使用 OpenAI 客户端与模型交互:
>>> import openai
>>>
>>> openai.api_base = "http://127.0.0.1:8000/v1"
>>> response = openai.ChatCompletion.create(model="default-model", messages=[{"role": "user", "content": "你好"}])
>>> response["choices"][0]["message"]["content"]
'你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'
有关流式响应,请查看示例客户端脚本:
OPENAI_API_BASE=http://127.0.0.1:8000/v1 python3 examples/openai_client.py --stream --prompt 你好
借助此 API 服务器作为后端,ChatGLM.cpp 模型可以无缝集成到使用 OpenAI 风格 API 的任何前端中,包括 mckaywrigley/chatbot-ui、fuergaosi233/wechat-chatgpt、Yidadaa/ChatGPT-Next-Web 等等。
使用Docker
选项1:本地构建
在本地构建docker镜像并启动一个容器以在CPU上运行推理:
docker build . --network=host -t chatglm.cpp
docker run -it --rm -v $PWD:/opt chatglm.cpp ./build/bin/main -m /opt/chatglm-ggml.bin -p "你好"
docker run -it --rm -v $PWD:/opt chatglm.cpp python3 examples/cli_chat.py -m /opt/chatglm-ggml.bin -p "你好"
docker run -it --rm -v $PWD:/opt -p 8000:8000 -e MODEL=/opt/chatglm-ggml.bin chatglm.cpp \
uvicorn chatglm_cpp.langchain_api:app --host 0.0.0.0 --port 8000
docker run -it --rm -v $PWD:/opt -p 8000:8000 -e MODEL=/opt/chatglm-ggml.bin chatglm.cpp \
uvicorn chatglm_cpp.openai_api:app --host 0.0.0.0 --port 8000
对于CUDA支持,请确保已安装nvidia-docker。然后运行:
docker build . --network=host -t chatglm.cpp-cuda \
--build-arg BASE_IMAGE=nvidia/cuda:12.2.0-devel-ubuntu20.04 \
--build-arg CMAKE_ARGS="-DGGML_CUBLAS=ON"
docker run -it --rm --gpus all -v $PWD:/chatglm.cpp/models chatglm.cpp-cuda ./build/bin/main -m models/chatglm-ggml.bin -p "你好"
选项2:使用预构建镜像
CPU推理的预构建镜像已发布在Docker Hub和GitHub Container Registry (GHCR)上。
从Docker Hub拉取并运行示例:
docker run -it --rm -v $PWD:/opt liplusx/chatglm.cpp:main \
./build/bin/main -m /opt/chatglm-ggml.bin -p "你好"
从GHCR拉取并运行示例:
docker run -it --rm -v $PWD:/opt ghcr.io/li-plus/chatglm.cpp:main \
./build/bin/main -m /opt/chatglm-ggml.bin -p "你好"
预构建镜像还支持Python示例和API服务器。使用与选项1相同的方式使用它。
性能
环境:
- CPU后端性能在一台Linux服务器上测量,使用Intel(R) Xeon(R) Platinum 8260 CPU @ 2.40GHz,使用16个线程。
- CUDA后端性能在一台V100-SXM2-32GB GPU上测量,使用1个线程。
- MPS后端性能在一台Apple M2 Ultra设备上测量,使用1个线程(目前仅支持ChatGLM2)。
ChatGLM-6B:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| 毫秒/标记 (使用Platinum 8260 CPU) | 74 | 77 | 86 | 89 | 114 | 189 |
| 毫秒/标记 (使用V100 SXM2 CUDA) | 8.1 | 8.7 | 9.4 | 9.5 | 12.0 | 19.1 |
| 文件大小 | 3.3G | 3.7G | 4.0G | 4.4G | 6.2G | 12G |
| 内存使用量 | 4.0G | 4.4G | 4.7G | 5.1G | 6.9G | 13G |
ChatGLM2-6B / CodeGeeX2:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| 毫秒/标记 (使用Platinum 8260 CPU) | 64 | 71 | 79 | 83 | 106 | 189 |
| 毫秒/标记 (使用V100 SXM2 CUDA) | 7.9 | 8.3 | 9.2 | 9.2 | 11.7 | 18.5 |
| 毫秒/标记 (使用M2 Ultra MPS) | 11.0 | 11.7 | N/A | N/A | N/A | 32.1 |
| 文件大小 | 3.3G | 3.7G | 4.0G | 4.4G | 6.2G | 12G |
| 内存使用量 | 3.4G | 3.8G | 4.1G | 4.5G | 6.2G | 12G |
Baichuan-7B / Baichuan2-7B:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| 毫秒/标记 (使用Platinum 8260 CPU) | 85.3 | 94.8 | 103.4 | 109.6 | 136.8 | 248.5 |
| 毫秒/标记 (使用V100 SXM2 CUDA) | 8.7 | 9.2 | 10.2 | 10.3 | 13.2 | 21.0 |
| 文件大小 | 4.0G | 4.4G | 4.9G | 5.3G | 7.5G | 14G |
| 内存使用量 | 4.5G | 4.9G | 5.3G | 5.7G | 7.8G | 14G |
Baichuan-13B / Baichuan2-13B:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| 毫秒/标记 (使用Platinum 8260 CPU) | 161.7 | 175.8 | 189.9 | 192.3 | 255.6 | 459.6 |
| 毫秒/标记 (使用V100 SXM2 CUDA) | 13.7 | 15.1 | 16.3 | 16.9 | 21.9 | 36.8 |
| 文件大小 | 7.0G | 7.8G | 8.5G | 9.3G | 14G | 25G |
| 内存使用量 | 7.8G | 8.8G | 9.5G | 10G | 14G | 25G |
开发
单元测试和基准测试
要进行单元测试,请添加以下CMake标志-DCHATGLM_ENABLE_TESTING=ON,以启用测试。重新编译并运行单元测试(包括基准测试)。
mkdir -p build && cd build
cmake .. -DCHATGLM_ENABLE_TESTING=ON && make -j
./bin/chatglm_test
只进行基准测试:
./bin/chatglm_test --gtest_filter='Benchmark.*'
Lint
要格式化代码,请在build文件夹内运行make lint。您应该预先安装clang-format,black和isort。
性能
要检测性能瓶颈,请添加CMake标志-DGGML_PERF=ON:
cmake .. -DGGML_PERF=ON && make -j
在运行模型时,这将打印每个图操作的时间。